
In a previous post, I wrote about how steps and variables become part of a "snapshot" when a release is created in Octopus. I mentioned that one of the changes I am working on is to introduce the concept of a 'role' into Octopus.
How it used to work
To recap, in the 1.0 versions of Octopus Deploy, an environment has machines, and steps in a project reference those machines:
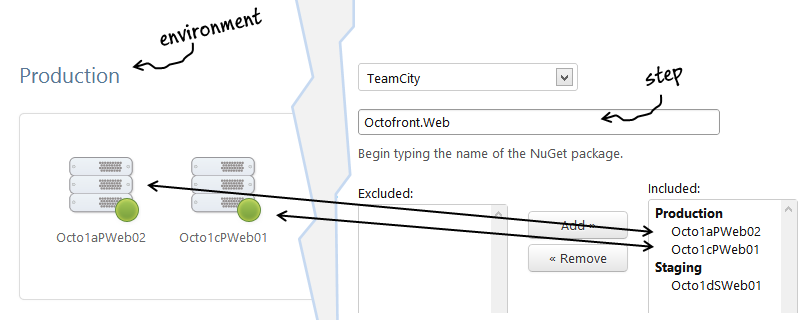
In the example above, I'm creating a step for a NuGet package, and I've selected two machines from the production environment.
This design has downsides:
- If you add or remove a machine, you'll have to update every project, and create new releases
- Old releases will not be deployed to the new machine, or will not be allowed to deploy if they reference a non-existent machine
In a world of cloud computing and scaling out, this is very problematic, and so I've been working on a fix.
How it will work
In Octopus Deploy 1.1, you'll be able to tag machines as serving one or more 'roles', which you can define yourself.

When you create a step or a variable, instead of choosing machines specifically, you'll just choose a role to target:

The same applies to variables - a variable can now be scoped to a 'role' instead of to a machine.
Upgrading
For customers with existing data in Octopus Deploy, this creates a problem. Previously, steps referenced machines. In the new model, steps reference roles, and machines are in roles. The two data models are incompatible, and I'm trying to decide how the migration experience will work.
There seem to be a few options. One is to break backwards compatibility - old releases/projects could become read-only, and users will have to visit each project to create new releases after defining the roles and updating steps/variables. Only then would you be able to deploy releases again. Obviously this has a lot of downsides.
Option 2 is to keep backwards compatibility indefinitely, by supporting both models. While this might be a better short term experience, in the long term I think it would just create confusion, as there would be two ways to do the same thing. The role-based model has no real downsides compared to the old model, so supporting the old model indefinitely makes no sense.
Finally, option 3 is to "adapt" the data, by automatically giving each machine a unique role (e.g., "machine-123"), and then converting old steps/variables that referenced that machine to reference its unique role instead. This way we move everything to a role-based model, old releases can continue to be deployed, and users can tidy up/refactor the roles as necessary after upgrading. It might be confusing at first, but Octopus Deploy users are all very clever, so I think they can handle it :)
Summary
Dealing with this kind of semantic difference in schema versions is an interesting problem, and at the moment I am leaning towards option 3.
If you are using Octopus Deploy at the moment, how would you expect the upgrade to work? Leave a comment in the box below :)


